

The Systems Approach has been the guiding principle for how we write, teach, and design systems for almost 30 years, and of course we get asked to define “Systems Approach” quite often. Sometimes it can be helpful to look at what the Systems Approach is not, which is the perspective that led to this week’s post.
When trying to define the Systems Approach, we usually focus on the “big picture” or “end-to-end” view. (Here is an example from our recent podcast.) But it’s also helpful to explain by counter-examples, where focusing too tightly on optimizing in just one dimension leads to an outcome that doesn’t work well for the whole system. I was reminded of this in Larry’s post last week. When I look for counter-examples from my own experience, the development of MPLS traffic engineering (MPLS-TE) comes to mind. While I was involved (1996 to about 2007) I think our approach could be more appropriately described as a series of focused optimizations than a systems approach. That was not the end of the story, fortunately, as there were significant advances in traffic engineering, largely enabled by SDN. I think these later approaches come closer to the Systems Approach, so in this post I want to examine the path from point optimization to systems approach as I followed the development of traffic engineering over 25+ years.
I started working on MPLS, in its pre-IETF days, when I joined Cisco in 1995, with the vague idea that there might be something in layer-2 networking (particularly popular-at-the-time ATM) that could bring benefits to layer-3 networking, which was Cisco’s main business. This felt at times like mixing random ingredients together in a test-tube in the hope that something useful might emerge. The first genuinely useful idea that eventually became the core of MPLS was destination-based forwarding using labels–an idea that had, unbeknownst to us, been published at SIGCOMM as threaded indices a year earlier. Not too long after we started fleshing out the details of that idea, one of my team-mates, George Swallow (later the chair of the MPLS working group) walked into my office to pitch the idea that MPLS could be used for traffic engineering. (In those days we were still calling it tag switching, but almost everything we did eventually got renamed–relabelled if you will–as MPLS.)
My first reaction to the idea that we could use MPLS to send packets along a path other than the one chosen by IP routing was strongly negative. The essence of destination-based forwarding was to use all the IP routing protocols we knew and loved, not the untested ones proposed as part of ATM. Those protocols would send packets along the shortest path to the destination. But I was missing an essential piece of context: traffic engineering based on mapping aggregate demand onto capacity constraints was already established with a few influential Internet Service Providers, and it was actually one of the selling features of layer-2 networking for the WAN at the time. Several ISPs in those days used either ATM or Frame Relay switches in their backbones to interconnect routers, and were leveraging the traffic engineering features in these switches.
As a result, we went on to recreate within MPLS a set of constraint-based routing features inspired by those L2 switches. The ISPs in general ran their backbones as a single, big link-state routing area, which meant that each backbone router had a full map of the backbone topology. By annotating the links with their capacities and flooding that information along with routing updates, each router could determine the shortest path to any destination that had enough bandwidth for the expected traffic to that destination. The value of MPLS in this scenario is that the labels can be used to force traffic to follow a certain path, even if it's not the shortest–a feature that we used to illustrate with a topology known as the “fish picture”. More details on this can be found in our book.
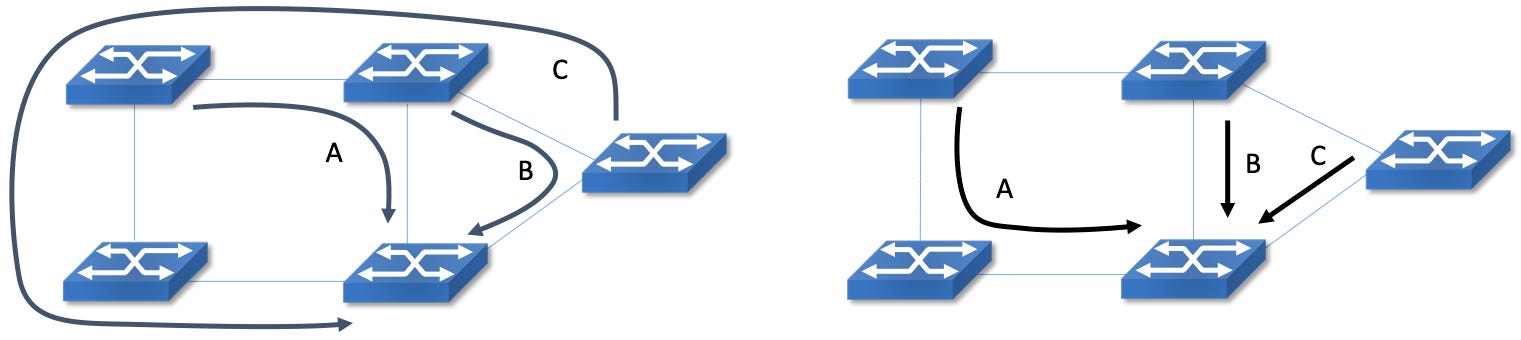
There are all sorts of challenges to be faced with this approach, and the solutions now fill a few dozen RFCs. One particularly thorny issue is that the placement of traffic in a distributed network of routers is inherently greedy. For example, suppose that in the network above we are trying to place three traffic flows of size L and that each link is also of capacity L. A greedy approach places each flow independently, which could lead to the suboptimal routes on the left rather than the much more efficient option on the right. In other cases a greedy approach could result in no feasible path being found even though a path exists. (We leave the details as an exercise for the reader.)
A partial solution to this problem is pre-emption (which was implemented as part of MPLS) but inevitably a greedy algorithm with limited coordination among the routers will run into scenarios where it either deadlocks or produces sub-optimal outcomes. At the time, our commitment to the idea that networks must not have central control meant we could only conceive of addressing this problem with ever more tweaks to the protocols, or with an offline planning tool. In the accepted wisdom of IP networking at the time, central control was forbidden. Planning tools that took a global view without directly controlling routers were OK, although far from popular. A couple of planning tools from third parties had modest success; the one I worked on did not. And that’s about as far as I went with traffic engineering.
Years later, I was excited when both Google and Microsoft published new approaches to traffic engineering that leveraged the global network view enabled by SDN. These were known as B4 and SWAN respectively. In essence, SDN broke the “rule” that centralized control could not be done, thus freeing the system from greedy approaches that made only local optimizations. With SDN, the networking community imported ideas from the systems community to build logically centralized controllers that were scalable and fault tolerant, countering the arguments about single points of failure and scalability that had stood for decades. Central controllers could look at the global traffic demands and map them intelligently onto the available network capacity. This was one of the main promises of SDN: that rather than thinking about networks in terms of device-level behavior we could treat the whole network as the system to be managed.
In the absence of SDN, we viewed traffic engineering as an incremental improvement to traditional routing, leading to a cascading series of tweaks and increasing complexity for MPLS-TE. But by taking a broader view of the overall system, and particularly the use of centralized control and the separation of control from forwarding, systems such as B4 and SWAN became possible and delivered (in my view) better solutions to traffic engineering. While it’s not easy to quantify the relative complexity of the systems, the performance benefits for B4 and SWAN are substantial.
There is a bit of the “innovator’s dilemma” in this story. Adding MPLS to the routing hardware and software of Cisco’s products was quite disruptive, but it was within the bounds of what was considered possible for a router company. Moving to centralized control, however, was viewed by most of my colleagues as too disruptive, especially as it raised the specter of commoditization of the routers themselves once enough software moved out of the routers. Combine this with a strong (and mistaken) belief that centralized control was the enemy of scale and reliability and it’s not hard to see why we stuck to local optimizations and resisted the SDN-based systems approach. It took companies with sufficient resources and lack of incumbency to embrace SDN for traffic engineering.
If you hunt around you can find a copy of “MPLS: Technology and Applications” on the used book market for more details of how MPLS-TE was developed. In news about other applications of SDN, there is a new Magma whitepaper and blog covering some of the key differentiators of Magma relative to other mobile packet core implementations. We’ll be talking about SDN with the Networking Channel on November 9. And in what looks like another positive step for network disaggregation, there is a new startup offering a supported version of SONiC.
I did not realize till now that you were only at Cisco 2 years earlier than I. Between you George, TonyLi ,Ranjeet and Azhar I would have just been just another router jock :-)